Token Maxxing — A Flex or Frustration?
AI is now the fastest-growing expense on corporate tech budgets. Here's how to manage token costs before your CFO does it for you.
By Kiran Sahota
In the spirit of AI adoption, organizations promote leaderboards to encourage usage — until the invoice shows up. AI is now the fastest-growing expense on corporate technology budgets. Cloud computing bills rose 19% in 2025 for many enterprises as generative AI adoption accelerated, and the organizations that led the charge on adoption are now the ones fielding the hardest questions from their CFOs.
The cloud parallel
The cost of AI is evolving just as fast as the technology itself. Those building it are still defining their pricing models. Those consuming it have little clarity on how pricing actually works. This dynamic is most analogous to what we experienced with cloud computing.
We are where we were with cloud circa 2006 — when AWS launched EC2 with consumption-based pricing and nobody really knew what their bill would look like at the end of the month. Today, organizations are learning how to manage their token consumption the same way they once learned to right-size EC2 instances.
Pricing Journey — Parallels Between Cloud and AI
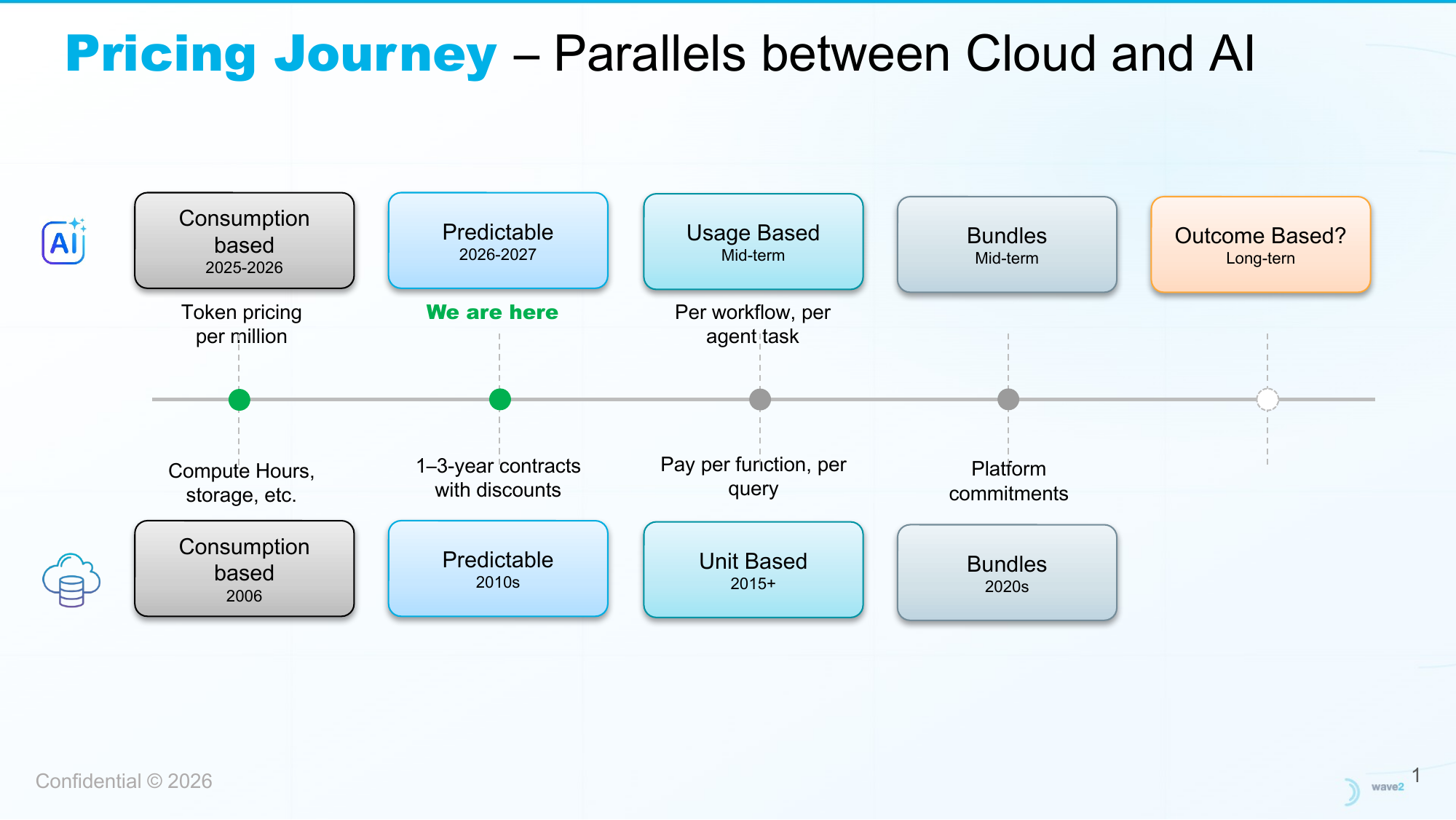
From compute-hour billing in 2006 to outcome-based pricing — AI is following the same arc as cloud.
The trajectory is clear: pricing will move up the stack, just as it did with cloud. But organizations that wait for the market to settle will overpay in the interim. The window to get ahead of this is now.
Five strategies to manage total cost of ownership
There is no single fix, but there are several levers organizations can pull today.
Cache your prompts. Most model providers offer 50–90% discounts on cached tokens. Caching means your AI reuses the computational work done on repeated prompts — but it only works on static prompts, not dynamically changing ones. This requires proper prompt management in place first.
Right-size your model. You do not need the best frontier model for every task. Build a selection framework: cheaper models handle simple Q&A and classification; premium models handle complex reasoning and synthesis. The cost difference between a lightweight model and a frontier model can be 10–50x per token.
Optimize your context window. Stop hoarding context. Retain only what is essential. For retrieval-augmented generation (RAG), set a token budget for retrieved context while maintaining quality. Trimming unnecessary context can reduce token consumption by 20–40% without meaningfully impacting output quality.
Batch where latency is acceptable. Not everything needs to be real-time. Many model providers offer significant discounts for batch API processing — for use cases where a delay of minutes or hours is acceptable, this can yield material savings without changing the outcome.
Build observability. If no one is watching, there will be waste. Monitor consumption and spend at the use case level. You cannot manage what you cannot see, and without visibility, token costs compound silently.
Where contracts are heading
As with cloud, we are entering a phase where CFOs prefer predictability over flexibility. Enterprise AI contracts are moving in the same direction as cloud reserved instances: commit to one or three years and receive 30–60% discounts. This gives organizations cost certainty and gives providers the guaranteed revenue they need in the current IPO environment.
The more transformational shift is still ahead.
Over the past decade, cloud pricing moved steadily up the stack. In 2014, serverless functions (AWS Lambda) meant organizations stopped thinking about servers and started paying per function execution. Databases like RDS and DynamoDB charged for queries, storage, and throughput. SaaS platforms built on cloud — Snowflake, Databricks — charge for data processed. In many organizations today, raw compute is no longer the largest line item because it is bundled into broader enterprise agreements.
The same progression is coming for AI:
- Near term: Enterprise AI contracts move to committed spend with capacity discounts
- Medium term: Pricing moves up the stack — per workflow or per agent task, not per token
- Longer term: Bundled into the platform, the way Azure bundles compute into enterprise agreements. We will not be talking about tokens
FinOps is governance
FinOps is not a finance problem. It is another layer of AI governance — and it starts with what, where, and who before it gets to how much. Organizations that build use case-level cost visibility now will be the ones that can defend every AI line item to their board, scale confidently, and avoid the reactive cuts that follow surprise invoices.
The leaderboard era is ending. The accountability era is beginning.
Sources
- AI Tokens: How to Navigate Spend Dynamics — Deloitte Insights